EViews
تحلیل خروجی مدل در ایویوز

تحلیل خروجی مدل در ایویوز
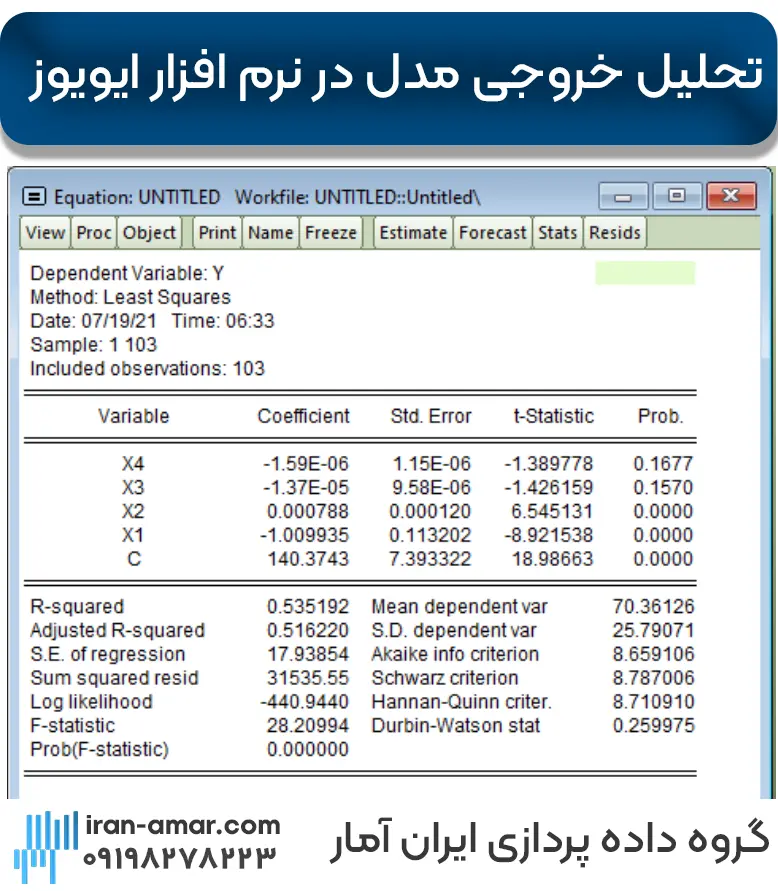
در آموزش برآورد مدل رگرسیونی در ایویوز مراحل اجرای مدل در نرم افزار ایویوز تا بخش مشاهده خروجی نرمافزار بررسی شده است. تصویر زیر خروجی مدل نرم افزار ایویوز است.
متغیر Y متغیر وابسته و متغیرهای X1 تا X4 متغیرهای مستقل مدل رگرسیونی هستند. تا انتهای آموزش تحلیل خروجی مدل در ایویوز به طور کامل بررسی شده است.
بررسی و تحلیل خروجی مدل در ایویوز
تحلیل خروجی مدل در ایویوز،بعد از برآورد مدل،خروجی بالا را مشاهده می کنیم که به ازای 103 مشاهده برای متغیر وابسته Y مدل شده است؛
برای شروع بررسی از معناداری ضرایب متغیر های مستقل شروع می کنیم:
ستون اول نام متغیر های مستقل Variable را نشان می دهد.
در این مدل 4 متغیر مستقل داریم و C که عرض از مبدا است.
بخش دوم Coefficient مقادیر ضرایب متغیر های مستقل را نشان می دهند.
در فرمول مدل اصلی مدل αi ها هستند.
ستون سوم انحراف معیار Std.Error را نمایش می دهند.
قسمت بعدی مقادیر آماری تی t.statistic را نشانم می دهد که حاصل تقسیم مقادیر ستون Coefficient بر ستون انحراف معیار Std.Error است.
ستون آخر با نام Prob به معنای احتمال گزارش شده است. این ستون احتمال معناداری ضرایب متغییرهای مستقل را نشان می دهد.
در سطح 95 درصد ضرایب متغییر های مدل معناداراند در صورتی که کم تراز 0.05 باشند.
در این مدل با توجه به خروجی بالا ضرایب متغیر X1 وX2 معنادار هستند ولی متغیر های X4 و X3 با ضرایب به ترتیب 0.1677 و 0.1570 که هر دو از 0.05 بیشتر هستند بر روی متغیر وابسته تاثیری ندارند.
بخش پایینی جدول اطلاعات مهمی را نرمافزار گزارش کرده است،که در ادامه به بررسی آن پرداخته شده است.
ضریب تعیین:(R-squared)
تحلیل خروجی مدل در ایویوز،اولین آماره گزارش شده R-squrared یا همان ضریب تعیین است. ضریب تعیین بیانگر این است که متغییرها مستقل مدل چند درصد از تغییرات متغییر وابسته را میتوانند توضیح دهند.
در خروجی نرمافزار برای مدل بالا ضریب تعیین عدد 0.535192 را نشان میدهد،که بیانگر این است که متغییرهای مستقل حدودا 54 از تغییرات متغییر وابسته را توضیح دادهاند.
ضریب تعیین هر چه به عدد یک نزدیک تر باشد مدل بهتری داریم؟؟برای پاسخ به این سوال در ادامهی آموزش همراه باشید.
ضریب تعیین تعدیل شده(Adj.R-squared)
آماره گزاش شدهی بعدی ضریب تعیین تعدیل شده است. این آماره همان ضریب تعیین است که به دلیل تاثیر درجه آزادی تعدیل شده است.
به طور ساده هر متغیری که به مدل اضافه میشود باعث افزایش ضریب تعیین مدل میشود این افزایش کاذب است و ضریب تعیین تعدیل شده این افزایش کاذب را جبران میکند.
احتمال معناداری مدل(Prob)
این آماره احتمال معناداری آماره F_Statistic است و در کل معناداری مدل را نتیجه می دهد،به طوری که اگر مقدار این احتمال کم تر از 0.05 باشد مدل معنادار است.
آماره دوربین واتسون (ِDurbin-Watson stat)
تحلیل خروجی مدل در ایویوز،آماره دوربین واتسون هم از آماره های مهم خروجی مدل رگرسیونی گزارش شده نرم افزار ایویوز
است.
آماره دوربین واتسون مختصرا بیانگر این است که آیا مدل دارای خود همبستگی جملات اخلال است.
عدم وجود خود همبستگی بین جملات اخلال از فروض کلاسیک برای برآورد می باشد.
مقادیر گزارش شده ی این آماره به صورت تجربی اگر بین 1.5 تا 2.5 باشد مشکل هم خطی در مدل وجود ندارد.
با لینک زیر می توانید به صفحه ی آموزش نرم افزار ایویوز رایگان،جامع و گام به گام EViews بروید.
آموزش نرم افزار ایویوز
سلام در توضیحات که نوشتیدضرایب متغیرx2وx3که با احتمال 0معنادارهستند متغیرهایx1وx2صحیح می باشد
ممنون از شما بله درست میفرمایید
اصلاح شد